
Rules, AI, and ML Walk Into a Crawler
March 5, 2026
I spent three months writing 18 hand-coded rules to determine which products a competitor sells by analyzing their website.
Then I tried to replace those rules with AI.
Then I tried to replace AI with a machine learning model.
Every time I tried to simplify, things broke. The system that finally works uses all three.
That sounds like bad engineering. It's actually the opposite. Here's the full story.
The problem: websites are messy
I'm building a competitive intelligence tool called Growth for Nuts. You give it a competitor's website. It reads every page and figures out what products and services the company sells. It compares what they offer to what you offer, finds the gaps, and tells you what to do about them. It also works like a time machine. You can see what your competitors changed in the past, and you'll know the moment they change anything in the future. No more getting caught napping.
The hard part isn't reading the website. Any script can pull text off a page. The hard part is figuring out which text actually matters.
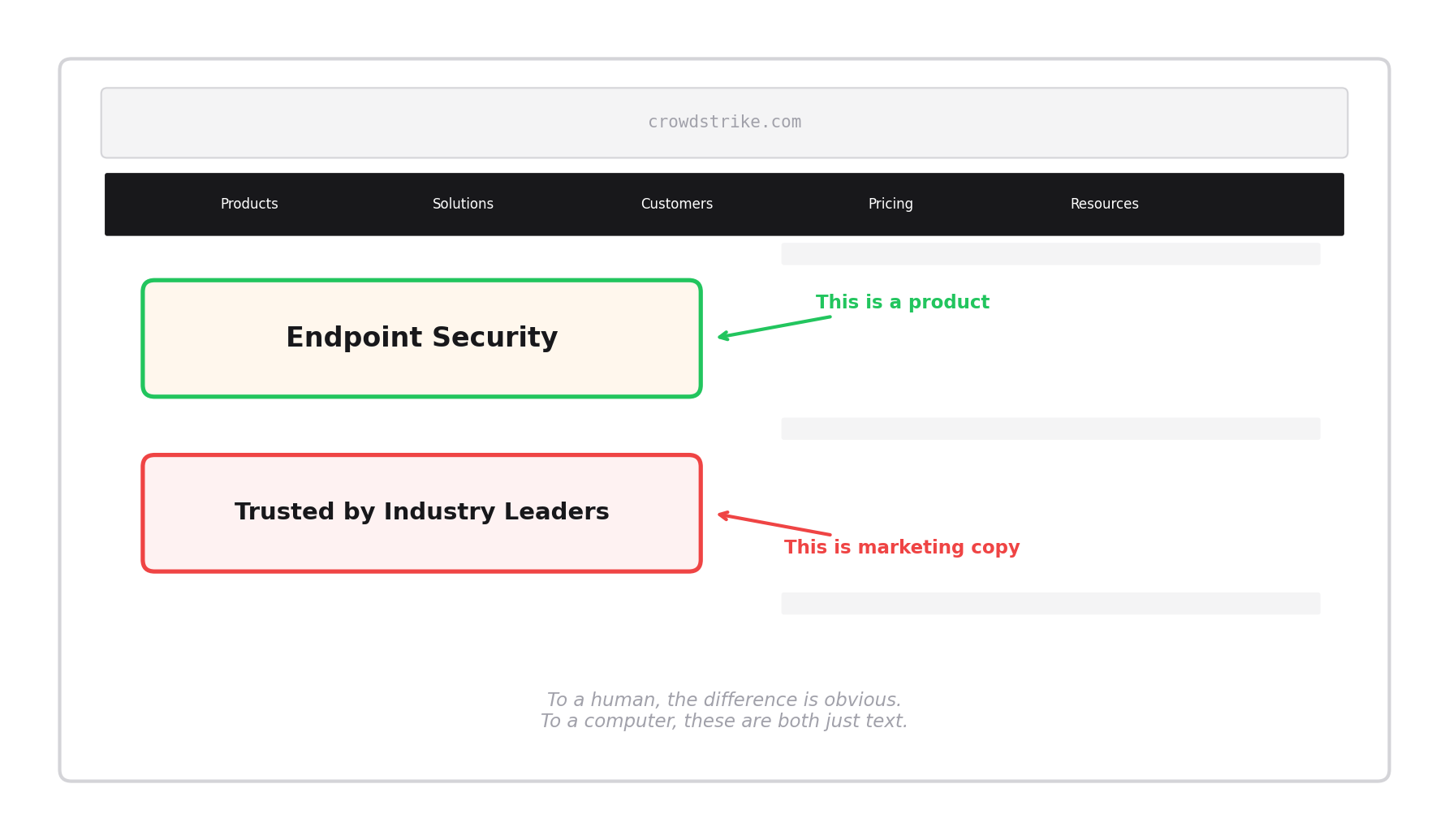
Take a company like CrowdStrike. Their website has hundreds of headings, links, and phrases. Some of them are real products: "Endpoint Security," "Threat Intelligence," "Cloud Security." Others are marketing copy: "Trusted by Industry Leaders," "Stop Breaches. Drive Business." Others are navigation junk: "Learn More," "Contact Sales," "EN-US."
To a human, the difference is obvious. To a computer, they all look the same. They're just strings of text pulled from HTML tags.
My job was to teach the computer to tell the difference.
Step 1: The 18 rules (December 2025)
I started with the simplest approach: a checklist. If a phrase matches a known pattern, throw it out.
Think of it like a mail sorter. Before you read any letter, you throw out everything that's obviously junk. Envelopes with no return address? Toss. Anything addressed to "Current Resident"? Toss. Anything that says "You may have already won"? Toss. You don't need to read the letter to know it's not worth your time.
That's what rules do. They catch the obvious garbage without thinking about it.
I wrote 18 of these rules. Here are a few:
If it looks like a phone number, throw it out. If it's a language selector like "Dansk" or "EN-US," throw it out. If it's a stat like "100+" or "$5M+ in revenue," throw it out. If it's a call-to-action like "Learn More" or "Get Started," throw it out. If it's two words smashed together with no space like "PipelinesScalable" (a common website glitch), throw it out.
These rules worked well for what they were designed to do. I tested them across 23 different industries. From a raw list of, say, 250 phrases pulled from a competitor's website, the rules would trim it down to about 100 by removing the obvious noise.
But 100 is still too many. And some real products got caught in the crossfire.
The rules had a fundamental limitation: they can't make judgment calls. The word "Shirt" should be thrown out if you're analyzing a SaaS analytics company. But it's a core product if you're analyzing a retail site. A checklist doesn't understand context. It just matches patterns.
I needed something smarter.

Step 2: Enter AI (January 2026)
I thought AI could replace the rules entirely. Just send everything to a large language model and let it decide what's a real product and what's noise.
Here's what that looks like in practice. I take a list of 100 phrases extracted from a competitor's website. I send them to an AI model with a simple instruction: "Which of these are actual products or services this company sells? And which are marketing copy, navigation elements, or other noise?"
The AI reads the list, considers the context, and gives me an answer for each one.
I started with Groq, a company that runs AI models very fast. Later, I switched to Google's Gemini, which I still use today.
The AI was genuinely good at judgment calls. It understood that "Endpoint Security" is a product, and "Powered by Experience. Driven by Excellence." is marketing fluff. It could tell that "Session Replay" is a real analytics feature and "Trusted by 10,000+ Companies" is a trust badge. It even rescued products that the rules had wrongly thrown out.
But two problems appeared quickly.
First, every AI call costs money and takes time. Each call is small (fractions of a cent, a few seconds). But I'm processing hundreds of websites with dozens of phrases each. The costs and delays add up. Running AI on every phrase from every page of every site turned what should be a fast automated process into a slow, expensive one.
Second, AI is inconsistent. Ask it the same question twice, and you might get two different answers. On Monday it might call "REST API" a product. On Tuesday it might call it a technical term. This is fine for a human assistant giving you a second opinion. It's a problem when you need a system that produces reliable, repeatable results.
I needed something that could make smart decisions without the cost and inconsistency of calling an external AI service every time.

Wait. Aren't AI and machine learning the same thing?
People use these terms interchangeably. In everyday conversation, that's fine. But they work differently in practice, and the difference matters for the rest of this story.
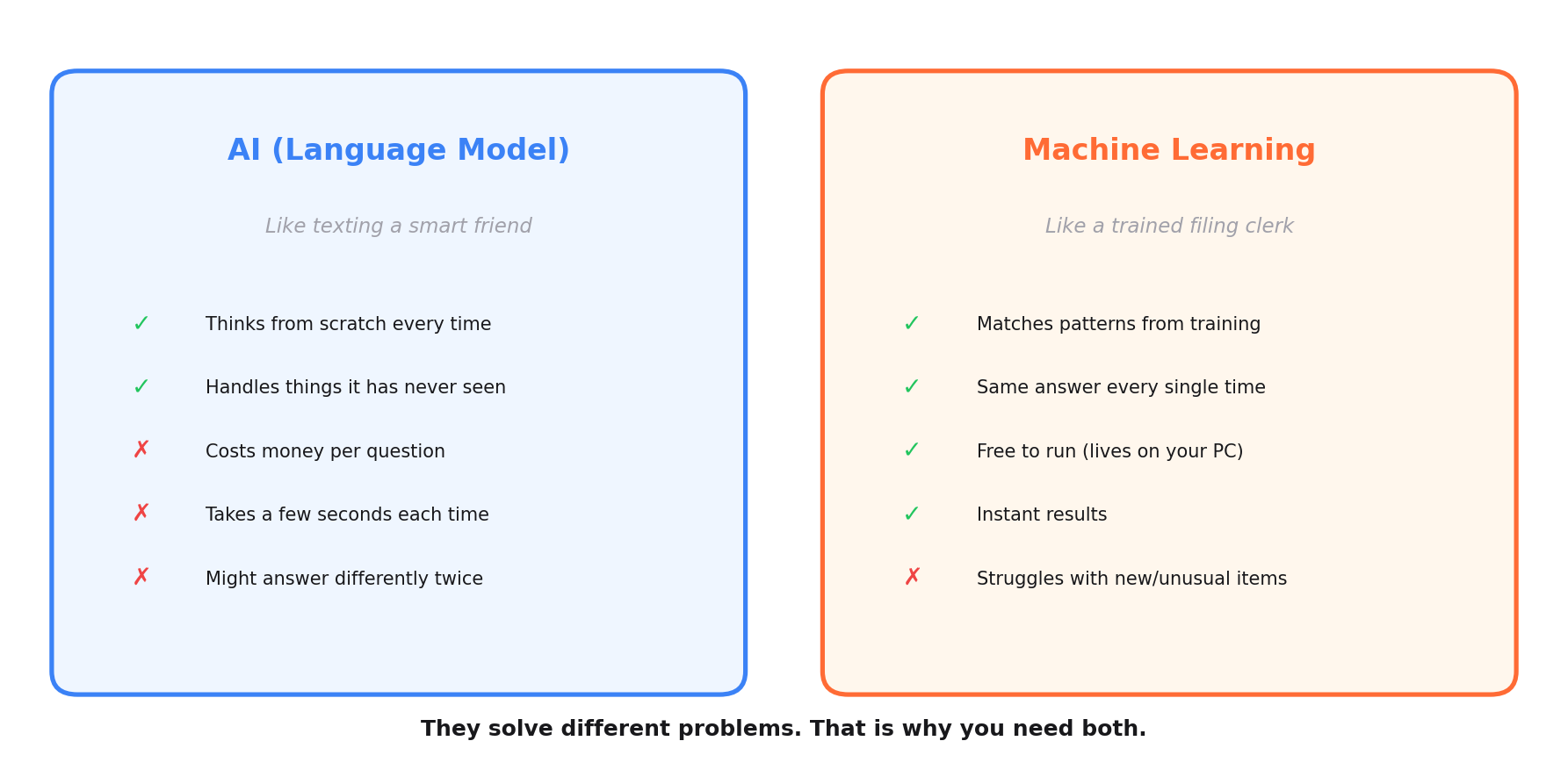
When I say "AI" in this post, I mean sending a question to a large language model (like Gemini or ChatGPT) over the internet and getting an answer back. Think of it like texting a very smart friend. Every question costs a small amount of money. It takes a few seconds to get a reply. And your friend might answer slightly differently each time you ask, because they reason through the question fresh every time.
When I say "machine learning" (or ML), I mean a small model that lives on my own computer. I trained it by showing it thousands of examples of right and wrong answers. It doesn't "think" the way a language model does. It matches patterns. Think of it like a filing clerk who has sorted 4,000 folders into "product" and "not a product" piles. After enough practice, the clerk knows where new folders go without asking anyone. The clerk is fast, works for free, and puts the same folder in the same pile every single time. But the clerk can't reason about something completely new that doesn't match any pattern from those 4,000 folders.
The smart friend is flexible but expensive and sometimes inconsistent. The filing clerk is rigid but fast, free, and perfectly consistent. You need both for different reasons.
Step 3: Enter machine learning (February 2026)
I thought: what if I train a model to make these decisions locally, on my own computer, without calling any external AI service? No cost per call. Instant results. Consistent every time.
Training a machine learning model is conceptually simple. You show it thousands of examples. "This is a product. This is noise. This is a product. This is noise." After enough examples, it learns the patterns and can classify new phrases on its own.
It's like training a new hire. You don't explain every possible decision they'll face. You sit them next to an experienced person for a few weeks. They watch 4,000 decisions being made. They pick up the patterns. Eventually, they can handle most decisions on their own, and they only ask for help on the unusual ones.
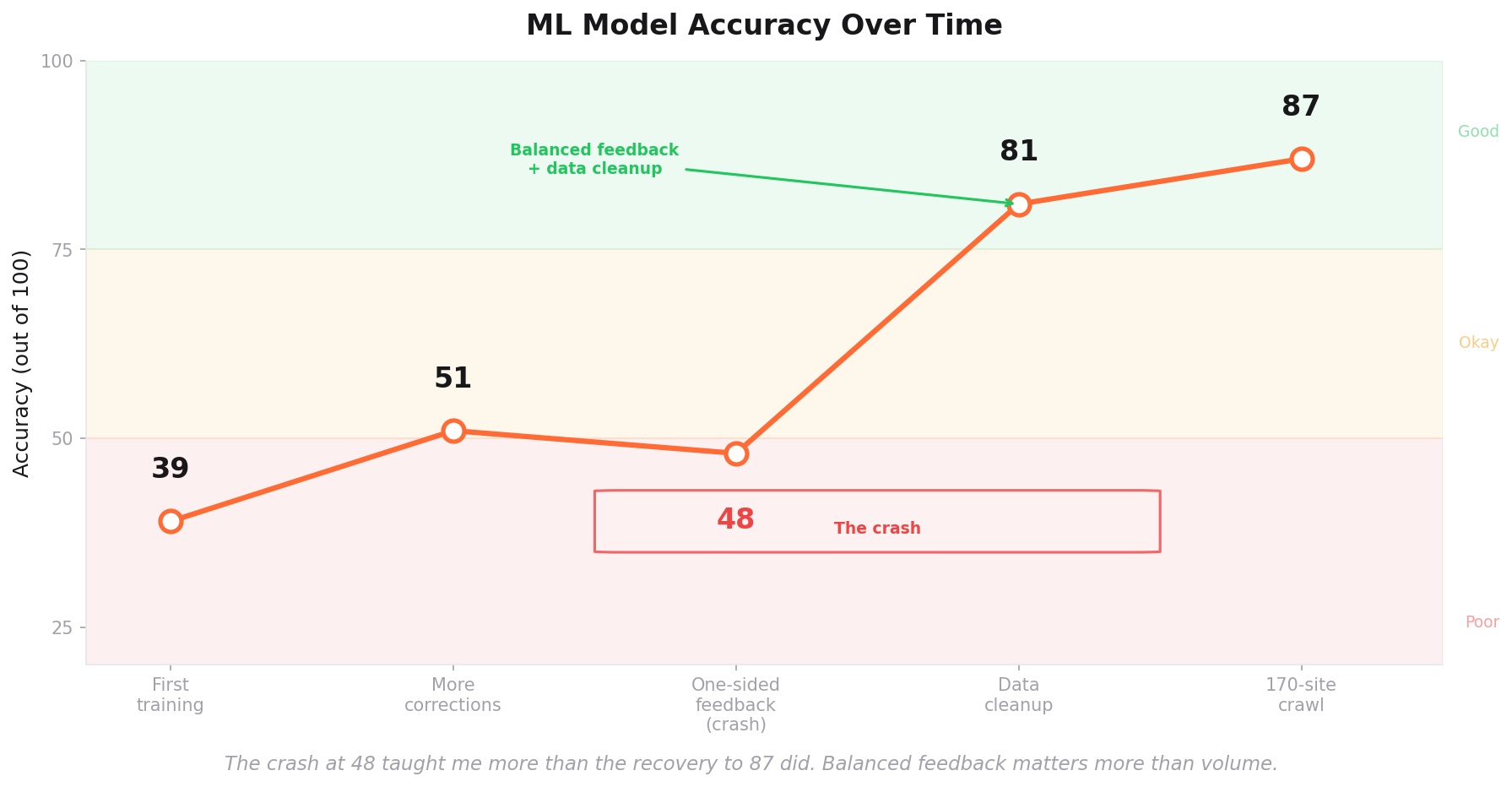
My first training run used about 1,900 examples. The model's accuracy was 39 out of 100. Terrible. Barely better than flipping a coin.
I kept feeding it corrections. Every time the model got something wrong, I told it the right answer and retrained it. The accuracy crept up to 51 out of 100. Still bad, but moving.
Then came the disaster.
I had accumulated 290 corrections. Every single one said the same thing: "This thing you classified as a product? It's actually noise." Not one correction said "Yes, this IS a real product. You got it right."
The model learned exactly one lesson: when in doubt, call it noise.
Its accuracy dropped to 48 out of 100. Worse than before.
I had taught the model to be a pessimist. It rejected everything.
I had to throw out those corrections and start over. This time I made sure the feedback was balanced. For every "that's not a product" correction, I also confirmed obvious real products: "Yes, Endpoint Security IS a product. Yes, Payroll Services IS a product." Balanced feedback gave the model a complete picture instead of a one-sided view.
Then I did something that made an even bigger difference. I went through all 4,000+ training examples and found 226 that were mislabeled. Phrases that had been marked as products but were actually noise, or vice versa. Cleaning those up was tedious but transformative.
After the cleanup and balanced retraining, the model jumped to 81 out of 100. Then I crawled more websites (170 sites across 19 B2B SaaS verticals), harvested new training data, and pushed it to 87 out of 100.
The lesson: machine learning is only as good as the data you train it on. Garbage in, garbage out is not a cliché. It's the most literal truth in this entire field.
Why I keep all three
Here's the part that surprised me. Every time I tried to kill one system, the other two got worse.
When I tried to replace rules with AI: The AI started spending time and money debating obvious garbage. Phrases like "EN-US" and "100+" and "PipelinesScalable" that no human would ever mistake for a product. The AI would reason about them, sometimes correctly, sometimes not. Meanwhile, a simple checklist handles these in microseconds with 100% accuracy. I was paying for intelligence I didn't need.
When I tried to replace AI with machine learning: The model couldn't handle edge cases. A phrase it had never seen before, from a vertical it had never trained on, would get a confident but wrong answer. The model doesn't know what it doesn't know. AI is better at the "I've never seen this before, but based on what it means, I think..." kind of reasoning. It can think from first principles. The model can only match patterns it's seen before.
When I tried to remove rules after adding ML: The model had to process thousands of extra garbage phrases per site. Things that should have been thrown out before they ever reached the model. The extra noise confused it. Accuracy dropped because it was making decisions on things that should never have reached it in the first place.
Each system's weakness is another system's strength.
Rules can't make judgment calls. But they catch technical garbage instantly and for free.
Machine learning can't handle things it's never seen. But it classifies familiar patterns faster and more consistently than AI.
AI can't run at scale without cost. But it reasons about unusual cases better than either rules or ML.
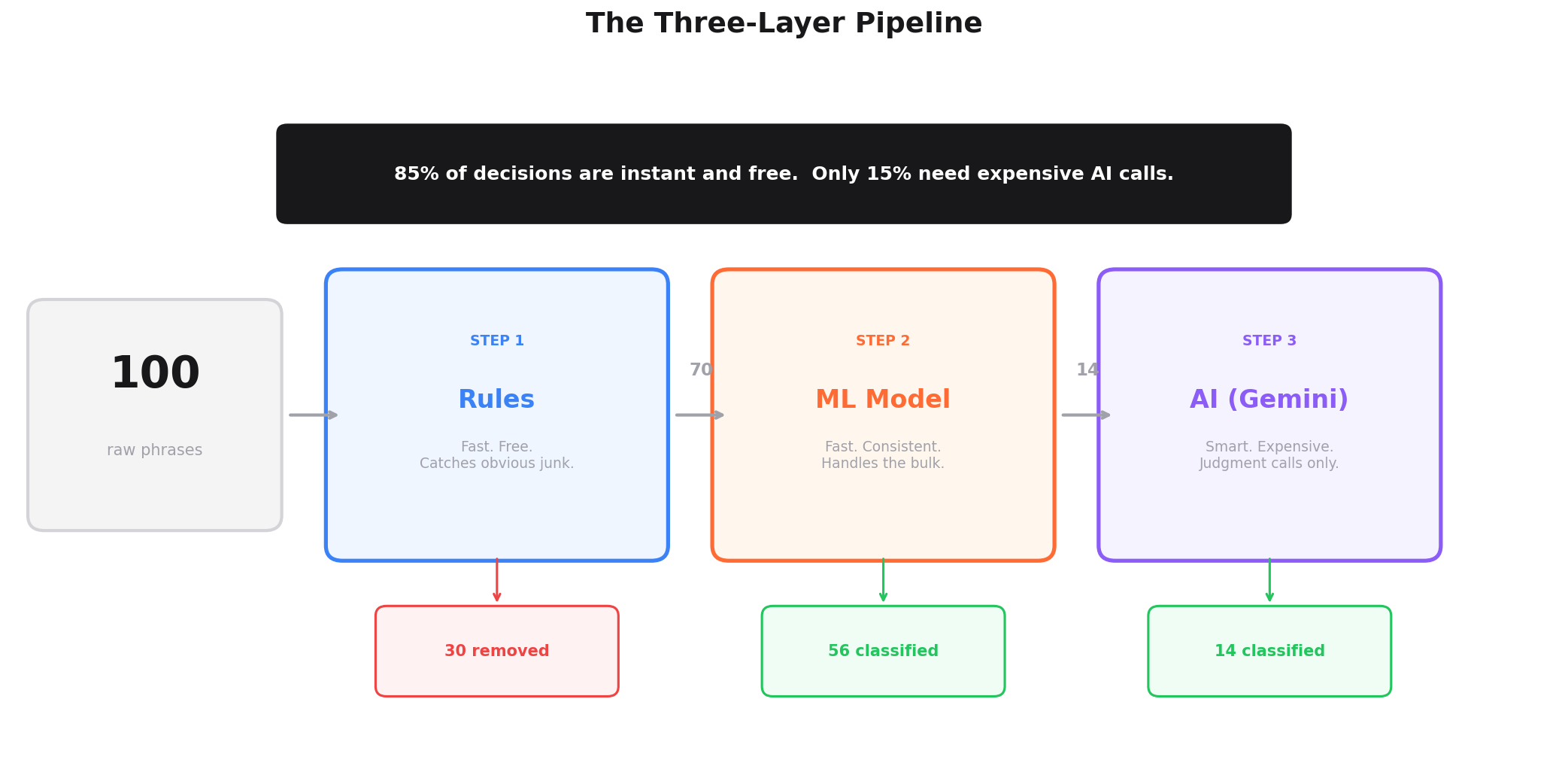
The architecture that finally works puts all three in sequence:
Step 1: Rules go first. They strip the technical garbage. Phone numbers, language selectors, concatenated strings, call-to-action buttons. This takes microseconds, costs nothing, and handles about 30% of all phrases. Everything that's clearly junk gets removed before anything else sees it.
Step 2: Machine learning goes second. It classifies the remaining 70%. For about 80% of those, it's confident enough to decide on its own. "Yes, this is a product" or "No, this is noise." These decisions are instant, free, and consistent. For the other 20% where confidence is low, it flags them as "uncertain" and passes them along.
Step 3: AI goes last. It reviews only the phrases that machine learning couldn't decide on. These are the genuinely ambiguous cases that need real reasoning. This is the expensive step, but it only runs on about 15% of the original input.
The result: 85% of decisions are made instantly and for free by rules and ML. The remaining 15% get the full power of AI reasoning. Cost stays low. Speed stays high. Accuracy is better than any single system alone.
Where the numbers stand today
The system now crawls websites across 19 B2B SaaS verticals: product analytics, legal tech, HR tech, customer success, security, construction, edtech, and more.
The machine learning model has been trained on 4,289 examples and achieves 87% accuracy. It improves with every crawl through an automated feedback loop. When it makes a mistake, the correction gets saved. After enough new corrections accumulate, the model retrains itself.
The rules haven't changed much since December. They didn't need to. Technical garbage looks the same in every industry.
The AI calls have dropped dramatically. In January, AI reviewed every single phrase. Today it only reviews the uncertain 15%. That cut the cost and time by about 85%.
All three layers are doing less work individually, but the system as a whole is doing better work than any one of them ever did alone.
What this means if you're building something
If you're a non-technical founder building with AI assistance (and if you read my first post, you know I build everything with Claude), the instinct to simplify is strong. Every extra system feels like complexity you have to manage. You want one clean solution.
Fight that instinct when the problem has genuinely different parts.
The parallel in marketing is obvious. You don't run only paid ads. You don't run only SEO. You don't run only email. You run all three because each channel reaches customers that the others miss. Paid ads are fast but expensive. SEO is free but slow. Email is personal, but requires a list. Nobody argues that three channels is "bad marketing architecture." It's just how multi-channel growth works.
Same principle applies here. Three simple systems that each do one thing well will outperform one sophisticated system trying to do everything.
Ask: what is each tool best at? Put them in sequence. Let each one handle what it handles well, and pass the rest along.
What I'd do differently
1. Start with balanced feedback from day one. Don't wait for the model to crash before confirming obvious correct answers.
2. Clean your training data before you scale it. 226 bad labels out of 4,000 doesn't sound like much, but it held the model back for weeks.
3. Don't try to simplify too early. Let the architecture prove itself before you start cutting layers.
What's next
The three-layer system now powers everything else I'm building at Growth for Nuts. It's the engine behind the competitive intelligence crawler that monitors websites across 19 verticals, extracts pricing data, tracks integrations, and detects when competitors change their positioning.
I'll write about those pieces next. If you want to follow along as I build this in public, subscribe to the newsletter or follow me on Twitter.
And if you haven't read it yet, my first post explains how I set up the entire tech stack (website, CMS, email list, and AI prototype) for $20/month with zero coding skills: A Non-Technical Founder's Blueprint for Vibe Coding.
This entire system was built by a non-technical founder using AI-assisted vibe coding with Claude. I don't write code. I describe what I want and iterate until it works. The 18 rules, the ML training pipeline, the AI integration, the crawler that ties it all together. All of it built through conversation.